Combinatorial optimization (CO) is a long studied field of mathematics that seeks to find the optimal item in a set. However, as problem size grows, the number of items in the set explodes (i.e., grows combinatorially).
Many famous problems exist within this field, perhaps most notably the Travelling Salesman Problem; correspondingly, many methods exist to find
solutions to these challenging problems. However, these solutions seek exact results and are extremely slow - to address this, a new field called Neural Combinatorial Optimization (NCO)
began to use machine learning models to find approximate or sufficient solutions to these challenging problems much more quickly than existing solvers. In this project, we utilized NCO to create schedules
where constraints need to be frequently added or removed, making traditional CO solvers infeasible. Additionally, many of the required constraints for the scheduling are extremely challenging to form as a mathematical constraint,
making NCO even more attractive since constraints in NCO do not need to be set up as a mathematical equation to incorporate.
Open the dropdown below to see additional details of the research.
Neural combinatorial optimization (NCO) is a relatively new field of study that uses machine learning models to learn approximate, sufficient solutions to combinatorial optmization problems.
(See I. Bello et al or A. Garmendia et al for more information on the burgeoning field).
The main library used for the duration of this research project is "Reinforcement Learning for Combinatorial Optimization", or RL4CO, a library that PyTorch has
supported thanks to its maturity and feature-richness. This library utilizes the vast PyTorch reinforcement learning (RL) ecosystem to train RL models from scratch that solve bespoke combinatorial optimization
problems.
The advantages of NCO are numerous - the problem setup is greatly simplified, the training time of a model is often negligible, and the execution time of inferencing a model to solve the optimization
problem is miniscule compared to solving the optmization problem exactly. Perhaps the best feature of NCO is that adding or removing constraints is almost trivial, only requiring a new model be trained
with the new constraint function in place (often this entails simply modifying the "action mask", see the official Github repository or
the official "New Environment: Creating and Modeling" tutorial for examples of this). Below are examples from the
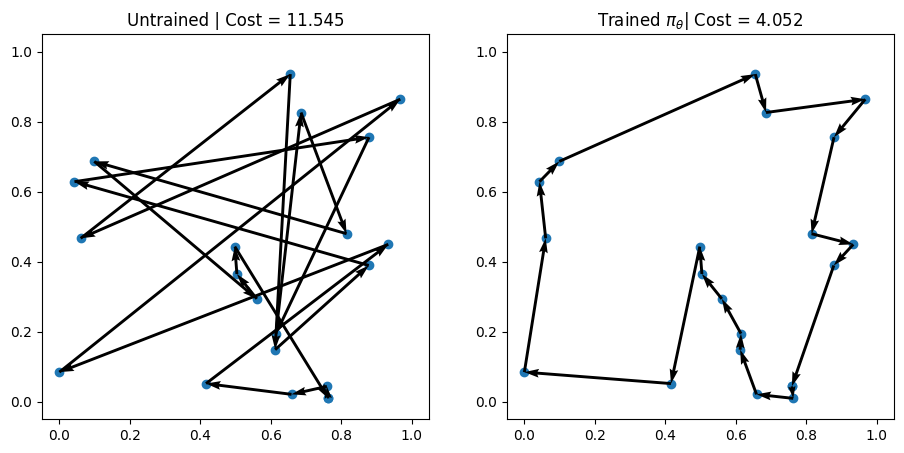
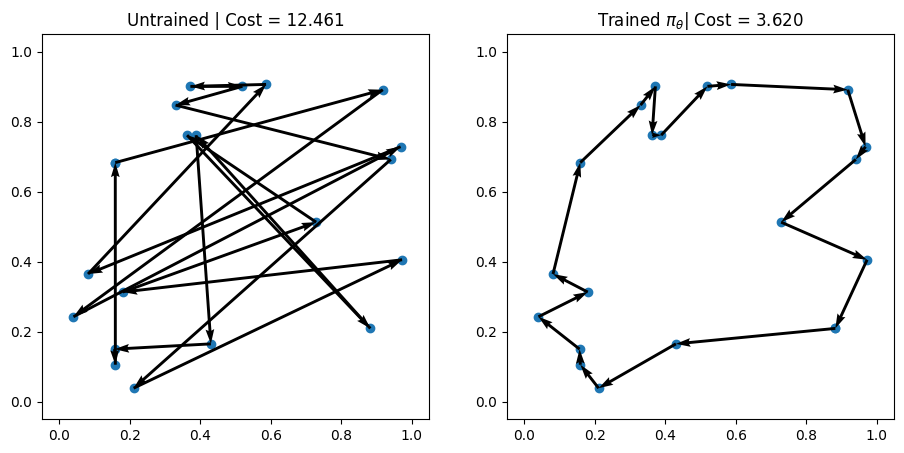
linked tutorial that demonstrate an example of NCO's effectiveness at solving combinatorial optimization problems quickly and sufficiently.
Two examples showing that, in only 3 epochs, the policy the model learned has been able to find significantly better solutions than random solutions. These solutions may not
be optimal, but are likely sufficient solutions to the problem.
Image credit: "New Environment: Creating and Modeling" RL4CO tutorial
Statistical Significance Testing for Model Comparison
The practice of directly comparing machine learning models on a certain test set, then reporting performance as a scalar-valued measure of goodness
is so ubiquitous that it can be found in almost every single AI/ML paper from the last 30 years. Many authors attempt to demonstrate variability in their
measurements by methods such as cross-validation, or calculating the average/median and standard deviation over randomized trials. However, these methods
(and other common methods of determining uncertainty in results) usually don't provide evidence of statistical significance between the proposed model and the
existing model. To address this, we utilized statistical techniques to determine if performance differences between models are statistically significant or not.
These tests were performed on the overall results and the by-category results, and across models that may have differing categories.
Open the dropdown below to see additional details of the research.
Specifically, we utilized Bootstrapping, a technique to estimate a desired statistic's true, population-level
value from only the current sample. This estimate is provided as a distribution, and the process can be seen in the figure below.
When we apply this technique to machine learning, we were primarily interested in two questions:
Which model is better overall, or by-category?
Does model performance differ when changes are made to the model or dataset?
Acheiving the first goal is a fairly straightforward application of the bootstrapping algorithm (see below for a demonstration) using each model's results vs the associated ground truths,
which allows us to collect evidence if one model is better at a statistically significant level or not. This sketch works for both the overall and by-category bootstrapping tests.
We were also interested in evaluating models when new categories were added to see if a small performance change between model versions was statistically significant or not.
If evidence was found that a performance dip was statistically significant, the model could be retrained or redesigned to ensure important categories were never underperforming
due to new categories being included in the dataset. When performance improvements were statistically significant, it was often because of wise design choices, or simply the addition or more data.
Alternatively, if performance changes were not statistically significant, then the model could be expected to perform the same as before but with the addition of a new category.
A diagram illustrating the process of bootstrapping. From a population, we have a sample (e.g. our dataset). We then resample with replacement from our sample as though it were
a true distribution. With each resample we compute a statistic on the samples we resampled, which provides a single datapoint in our new distribution. This final distribution is our
estimate of the population's statistic value.
Image credit: Wikipedia Bootstrapping article
For an excellent introduction and discussion to bootstrapping (and permutation testing, which was also used at stages), see An Introduction to the Bootstrap.
Detecting Out-of-Distribution Instances
Machine learning models usually make the assumption that any future test data the model encounters will be distributed similarly to the model's training data.
This makes the task of determining what is in-distribution (ID) vs out-of-distribution (OOD) an important task, since predictions from a model on OOD data
could result in poor performance. Often OOD data is split into two categories: covariate and semantic (see Wang et al
for more details). In this research, we determined there was an appreciable performance disparity in CV models when the testing set underwent covariate shift (e.g. day
vs night images), and in NLP models when the testing data underwent semantic shift (e.g. Wikipedia data vs Twitter data). To detect both covariate and semantic shift,
we developed a simple sliding window technique that utilized various summary statistics to raise an "alarm bell" when new data a model is encountering may be OOD,
warning users that predictions may be unreliable, and that model retraining may be merited.
Open the dropdown below to see additional details of the research.
Out of distribution detection is an old field, with many methods to address discovering out of distribution data. The field is closely related to
outlier detection (OD), and many methods can be used interchangably between the fields. For this research, the following constraints were in place:
OOD detection must be fast
An OOD score should be provided
The OOD detection method should be interpretable
These constraints removed many large OOD detector networks immediately, as they would never run quickly enough. However, many well researched methods for
outlier detection would also be insufficient since a score needed to be provided, and many outlier detection methods are binary. Finally, the detection method
needed to be interpretable so an engineer could determine when new data was truly too far out of distribution for the current model to be reliable.
To address these requirements, we utilized some well researched OD and OOD methods and modified them appropriately to function in sliding windows.
This allowed not just for fast OOD detection, but opened the possibility of streaming OOD detection.
These methods returned an OOD score, and with some reasonable tuning methods, we found a threshold value that raised almost no false positives at the cost of a few false negatives.
This score was also interpretable, as it ranged from [0, ∞] and users could compare scores to the threshold value and previous scores for context. This also
permitted easy visualization, and plots were created that allowed for non-technical individuals to see how in-distribution or out-of-distribution
new data was compared to the training data.
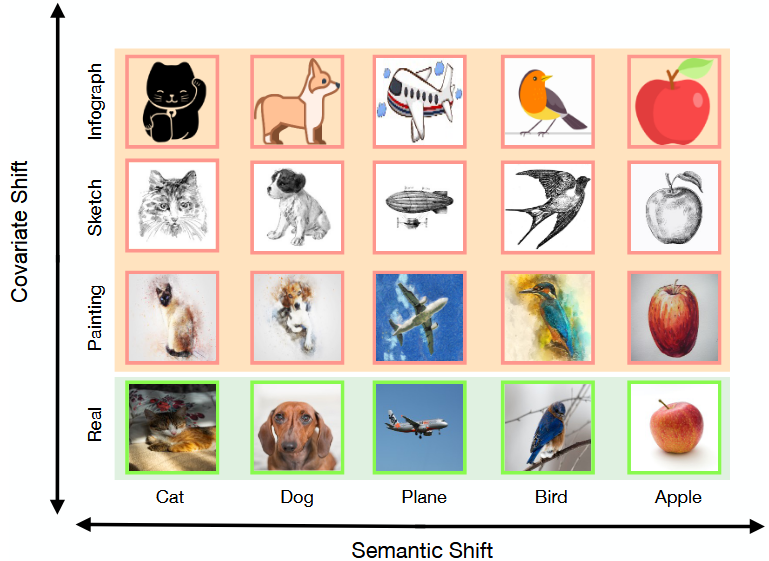
This image demonstrates the difference between covariate shift and semantic shift. Covariate shift occurs when the classes remain the same,
but instances change style, orientation, etc. Semantic shift occurs when the data contains new classes.
Image credit: Wang et al
Abstract:
In recent years, there have been significant efforts on mitigating unethical demographic biases in machine learning
methods. However, very little work is done for kernel methods. In this paper, we propose a novel fair kernel regression method
via fair feature embedding (FKR-F2E) in kernel space. Motivated by prior works feature processing for fair learning and feature
selection for kernel methods, we propose to learn fair feature embeddings in kernel space, where the demographic discrepancy
of feature distributions is minimized. Through experiments on three public real-world data sets, we show the proposed FKR-
F2E achieves significantly lower prediction disparity compared with the state-of-the-art fair kernel regression method and several
other baseline methods.
Abstract:
In music classification tasks, Convolutional Recurrent Neural Network (CRNN) has achieved state-of-the-art performance on several data sets. However, the current CRNN
technique only uses RNN to extract spatial dependency of music signal in its time dimension but not its frequency dimension. We
hypothesize the latter can be additionally exploited to improve classification performance. In this paper, we propose an improved
technique called CRNN in Time and Frequency dimensions (CRNN-TF), which captures spatial dependencies of music signal
in both time and frequency dimensions in multiple directions. Experimental studies on three real-world music data sets show
that CRNN-TF consistently outperforms CRNN and several other state-of-the-art deep learning-based music classifiers. Our results
also suggest CRNN-TF is transferable on small music data sets via the fine-tuning technique.